The main task here is gathering the data. After that, just run the provided scripts.

Collect and label the data (optional)
Supervised machine learning needs labelled data. The task of collecting and labelling this data is often overlooked in textbooks. Performing this step yourself is OPTIONAL, but you still need to understand the process.
Parameterise the data (optional)
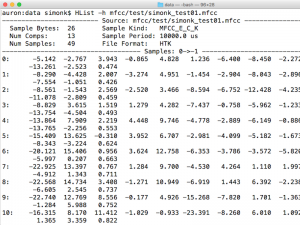
Our HMMs do not work directly with waveforms, but rather with features extracted from those waveforms. Performing this step yourself is OPTIONAL, but you still need to understand the process.
Train the acoustic models
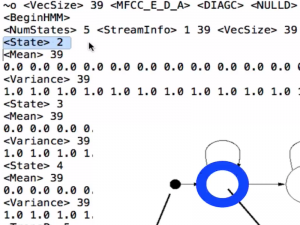
We will used supervised machine learning (including the Baum-Welch algorithm) to train models on labelled data.
Evaluation
By comparing the recogniser's output with the hand-labelled test data, we can compute the Word Error Rate (WER).