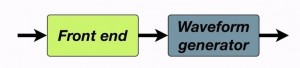
Most text-to-speech systems split the problem into two main stages. The first stage is called the front end and contains many separate processes which gradually build up a linguistic specification from the input text. The second stage typically uses language-independent techniques (although they still require a language-specific speech corpus) to generate a waveform. Here we see those two […]