
Before continuing, you should check that you have the right background by watching this video.
Interactive toy demo

A short video demonstration of unit selection. You can find the actual interactive demo on this website. Have a play with it yourself!
Search
With multiple candidates available for each target position, a search must be performed.
Target cost and join cost

To choose between the many possible sequences of candidate units, we need to quantify how good each possible sequence will sound.
Target and candidate units

We use the linguistic specification from the front end to define a target unit sequence. Then, we find all potential candidate units in the database.
Key concepts

Linguistic context affects the acoustic realisation of speech sounds. But several different linguistic contexts can lead to almost the same sound. Unit selection takes advantage of this “interchangeability”.
October 31, 2015
The speed of sound

At the Parque de las Ciencias in Granada, Spain there is this long tube, open at the end nearest you and closed at the far end. We can calculate the length of this tube just from the audio recording, because we know the speed of sound. Here’s the waveform of part of the recording, showing […]
October 30, 2015
Wave propagation on the surface of water

At the Alhambra (Granada, Spain) I saw this nice example of waves from a point source propagating in all directions at a fixed speed.
February 1, 2015
Autocorrelation for estimating F0
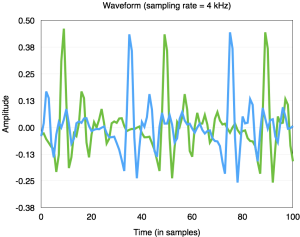
Most methods for estimating F0 start from autocorrelation. The idea is pretty simple: we are just looking for a repeating pattern in the waveform, which corresponds to the periodic vocal fold activity. For some waveforms, it might be possible to do that directly in the time domain, but in general that doesn’t work very well. […]
November 23, 2014
The Gaussian probability density function: understanding the equation
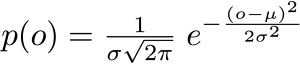
The equation for the Gaussian probability density function looks a little scary at first, but this video should help you understand what each of the terms is doing, and how they fit together. After watching the video download the spreadsheet which shows the calculations and plots from this video (tip: the Apple Numbers.app version includes images […]
November 15, 2014
Token passing
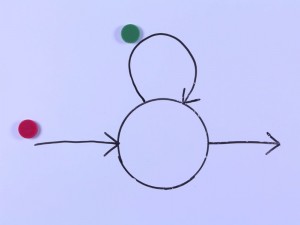
Token passing is a really nice way to understand (and even to implement) Viterbi search for Hidden Markov Models. Here we see token passing in action, and you can look at the spreadsheet to see the calculations. To keep things simple, we are ignoring transition probabilities in this example. It would be simple to add them […]
October 18, 2014
TD-PSOLA …the hard way
Time-Domain Pitch Synchronous Overlap and Add (TD-PSOLA) can modify the fundamental frequency and duration of speech signals, without affecting the segment identity – that is, without changing the formants. Normally, it’s an automatic algorithm, but here we do it the hard way – by hand! If you want to follow-along, you will need Audacity and these materials (a […]