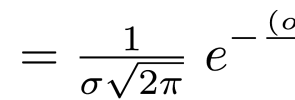At the Parque de las Ciencias in Granada, Spain there is this long tube, open at the end nearest you and closed at the far end.
We can calculate the length of this tube just from the audio recording, because we know the speed of sound.
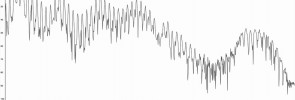
Here’s the waveform of part of the recording, showing one handclap followed by the sound of the echo. I’ve removed the time axis.
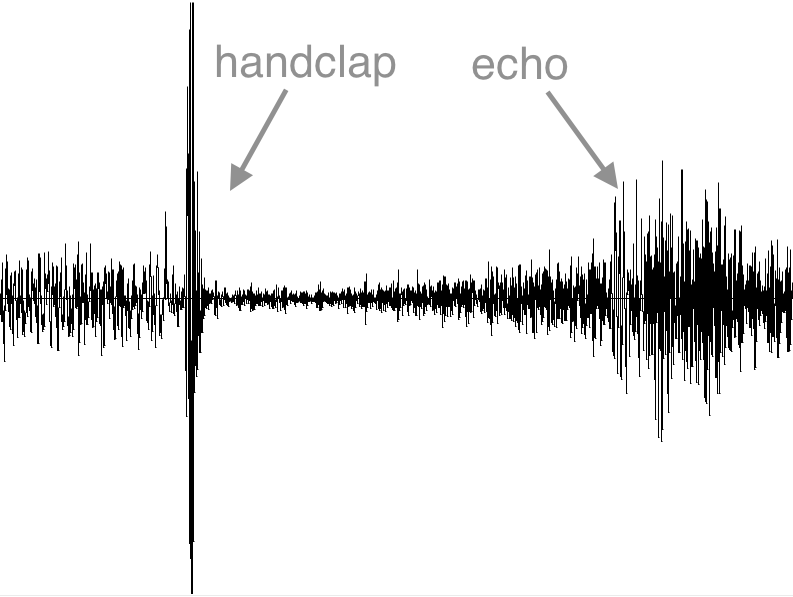
And here’s part of the audio track from the video for you to download (right click, save as…) and open in Wavesurfer or your favourite editor.
Now try to do the calculation yourself (hint: the sound of the handclap has to travel to the far end of the tube, be reflected, then come all the way back). You can assume the speed of sound is 337 metres per second.